AI 换脸是通过深度学习算法将图像或视频中的面部特征替换为另一人的技术。其底层逻辑是利用编码器提取面部关键点,再由解码器在目标画面上重建特征。截至 2026 年 3 月,该技术已从简单的像素覆盖演进至基于扩散模型(Diffusion Models)的实时高保真重建,使得在消费级硬件上实现电影级视觉效果成为可能。
目前的 AI 换脸已分化为两条路径:一是追求极低延迟的实时流媒体换脸,二是追求绝对真实感且允许长时间渲染的离线生成。初学者若混淆两者,在需要高精度输出时误用实时工具,画面会出现明显的“面具感”或边缘闪烁。
核心原理:从 GAN 到扩散模型的跨越

换脸效果的提升源于底层数学逻辑的变更。早期的生成对抗网络(GAN)依赖生成器与判别器的博弈,但其训练不稳定,容易出现“模式崩溃”,导致人脸在特定角度突然扭曲。
当前主流方案转向潜在扩散模型(Latent Diffusion Models)的微调。以 Flux 架构为例,它通过 LoRA(低秩自适应)将特定人物的面部权重注入预训练模型,在潜在空间中对人脸进行重绘,而非简单的特征覆盖。这种方式让 AI 能根据场景光影重新绘制面部,解决了长期存在的“光影不匹配”问题,使皮肤质感能随环境光变化。
本地部署实操:FaceFusion 与 Flux LoRA
对于在意隐私和质量的用户,本地化部署是最佳选择。目前成熟的工作流分为“快速替换”和“精细重绘”两套方案。
方案一:使用 FaceFusion 进行视频换脸
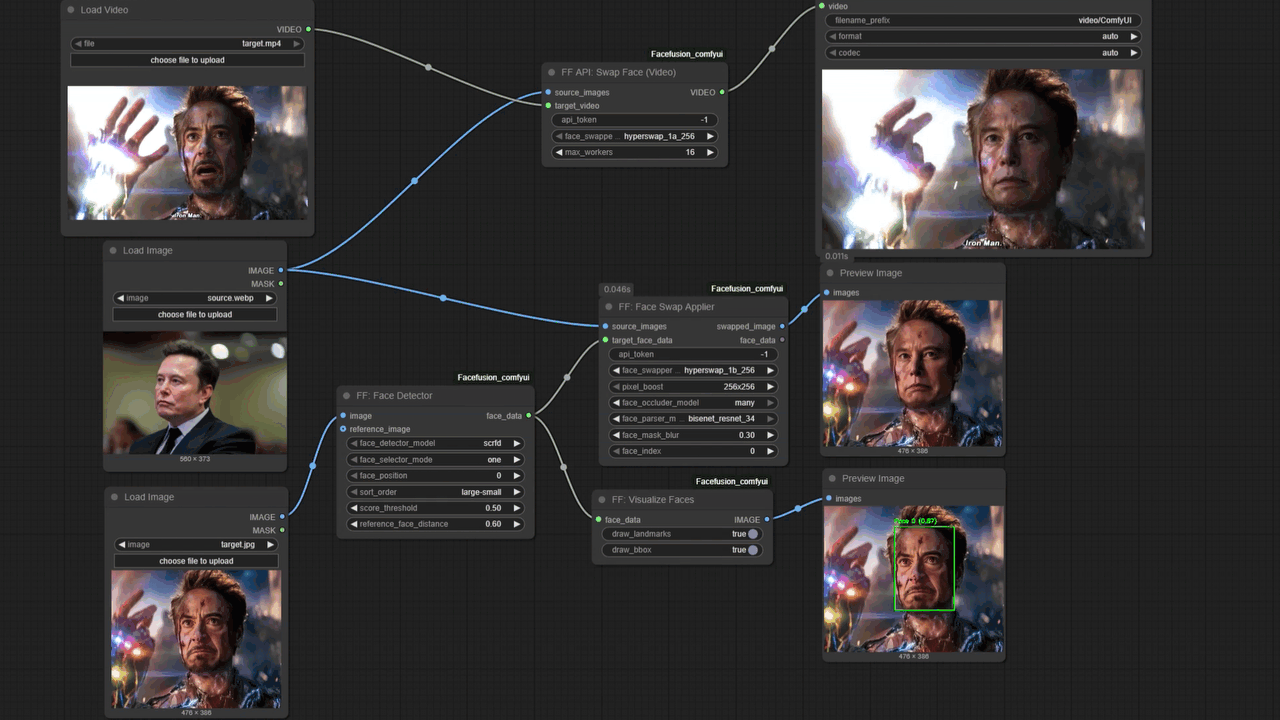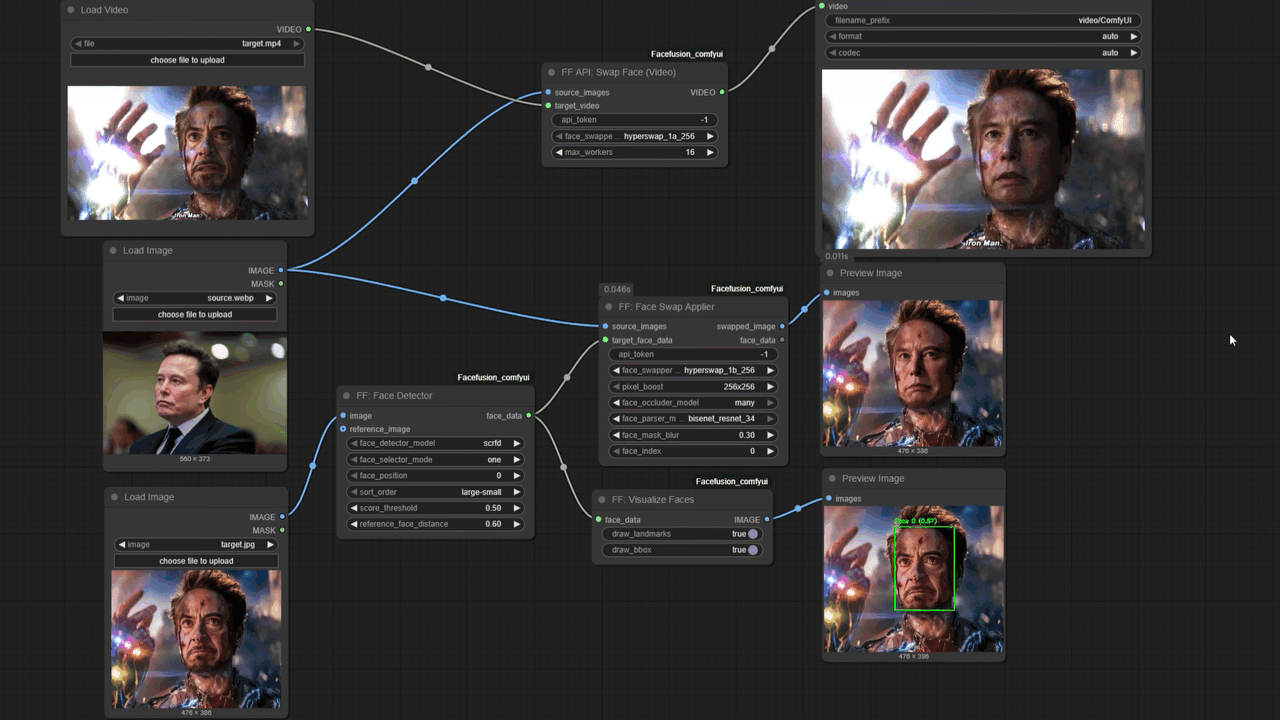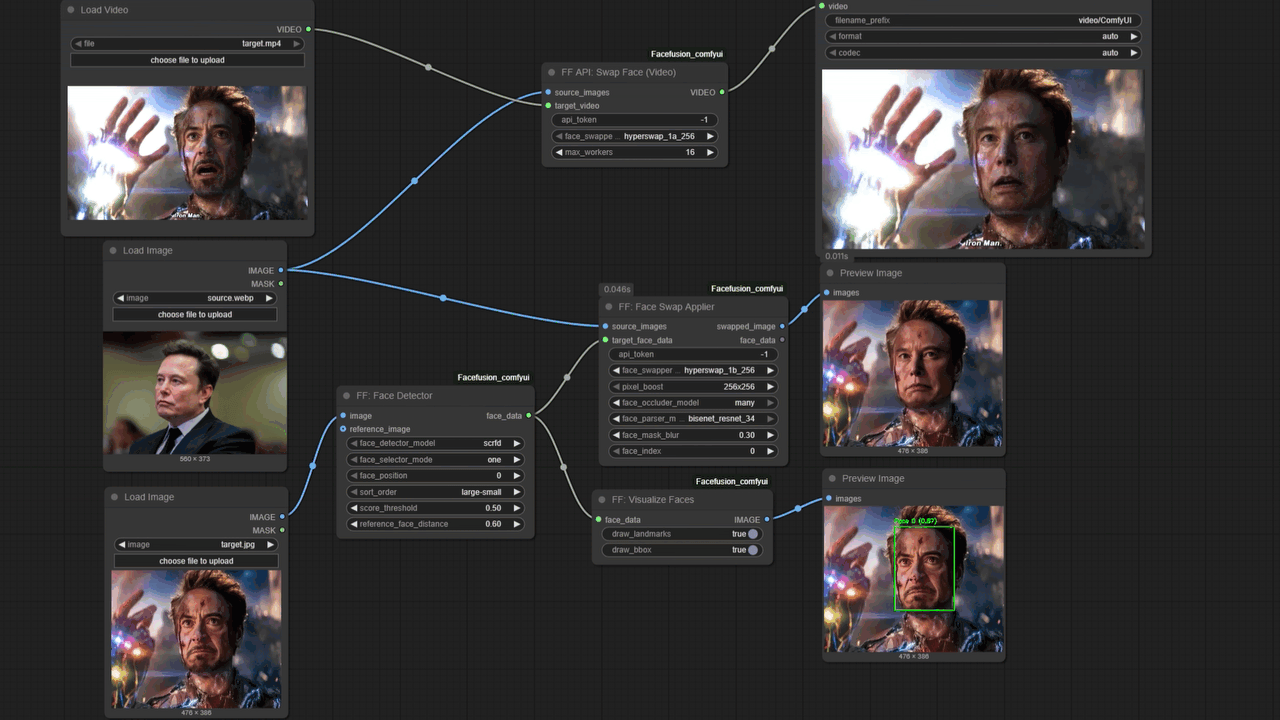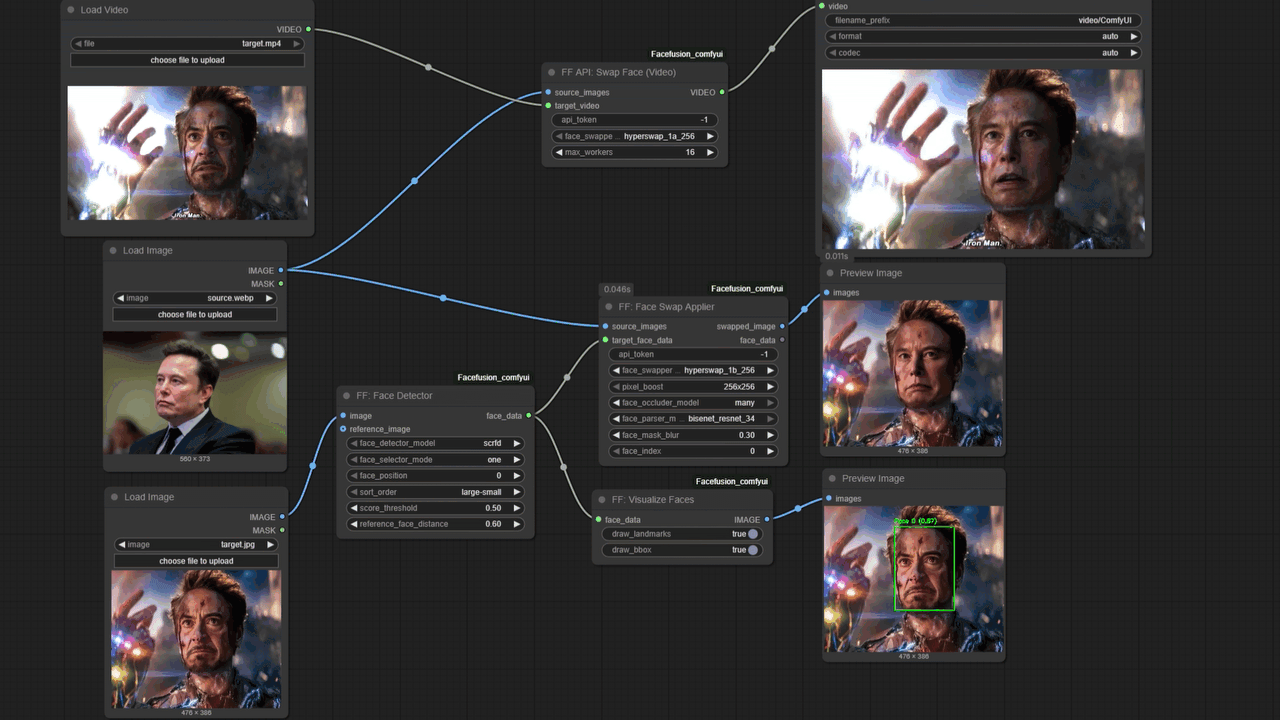
FaceFusion 适合处理长视频且硬件配置中等的场景。
onnxruntime-gpu 而非 CPU 版本,否则渲染速度将下降约 20 倍。
retinaface,其在处理侧脸或遮挡时的稳定性优于 yolov5。若源图对比度不足,需先进行亮度修正,否则生成面部会缺乏立体感。
inswapper_128 或更新模型。若出现模糊感,应开启 Face Enhancer 并选择 GFPGAN 或 CodeFormer,权重建议在 0.5-0.8 之间。权重过高会抹除皮肤毛孔,产生塑料感。
方案二:使用 Flux LoRA + Inpaint 实现静态换脸
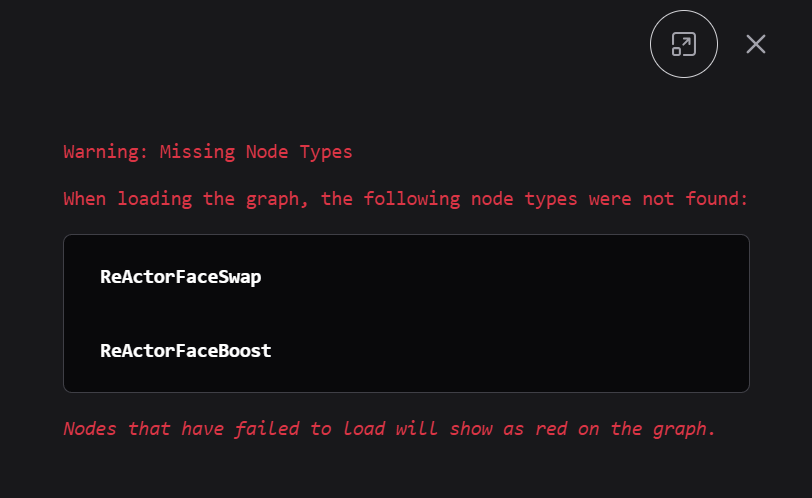
若追求绝对真实且不容忍面具感,Flux 架构的局部重绘(Inpaint)是目前的上限。
.safetensors 权重文件。
Euler,步数 25-30 步。
实时换脸的局限与识别
实时换脸(Live Face Swap)在远程会议和面试中应用增加,但由于需要极高帧率,面部细节通常被简化。当使用者快速转头或有物体遮挡面部时,容易出现瞬间的“像素漂移”或闪烁。观察对方大幅度动作时的面部稳定性,是目前识别 AI 换脸最简单的方法。
三种主流方案对比
| 方案类型 | 典型工具 | 视觉效果 | 适用场景 |
|---|---|---|---|
| 实时换脸 | DeepFaceLive | 中等,易闪烁 | 直播、会议 |
| 快速离线换脸 | FaceFusion | 良好,细节增强 | 短视频、Demo |
| 扩散模型重绘 | Flux + LoRA | 顶级,光影真实 | 商业摄影、电影 |
三类不适用场景
极端侧脸(超过 60 度):由于缺乏深度信息,生成的轮廓容易扁平或拉伸,大角度转头会产生跳帧感。
快速移动的遮挡物:当手掌、发丝经过脸部时,AI 难以区分层级,导致脸部像素“跳”到遮挡物上方,产生视觉撕裂。
超高分辨率特写:在 4K/8K 镜头下,AI 通过锐化填充细节而非物理重建,缺乏自然皮肤的色素沉着和微小瑕疵,放大后质感过于均匀。
实践建议
普通用户应根据目的选择工作流。快速社交内容创作建议使用 FaceFusion,重点在于提升原视频拍摄质量,以降低对增强插件的依赖。
商业项目开发者应建立“多级验证”机制,尝试不同权重的 LoRA 进行多次生成并在后期合成。目前顶级效果通常由 70% 的 AI 生成与 30% 的人工调色共同完成。
面试官或审核员可通过“动态验证”识别伪装,如要求对方用手遮住半边脸或快速左右摆头,观察面部边缘的贴合度。
如何解决换脸后的边缘不自然问题?
可以通过降低重绘强度(Denoising strength)或在后期使用遮罩羽化处理。在 FaceFusion 中,尝试调整 Face Enhancer 的权重至 0.5 左右可减轻塑料感。
训练 LoRA 时照片质量对结果影响大吗?
极大。照片应包含多种光照条件和微表情,避免过度美颜的素材,否则模型会习得错误的皮肤纹理,导致生成结果缺乏真实感。
下一步尝试:
在 ComfyUI 中安装 Flux 相关节点,使用一张个人照片尝试 Inpaint 重绘。重点观察 Denoising strength 在 0.4-0.6 之间的变化,理解“相似度”与“真实感”的权衡,这是掌握 AI 换脸实操的第一步。